InLocus
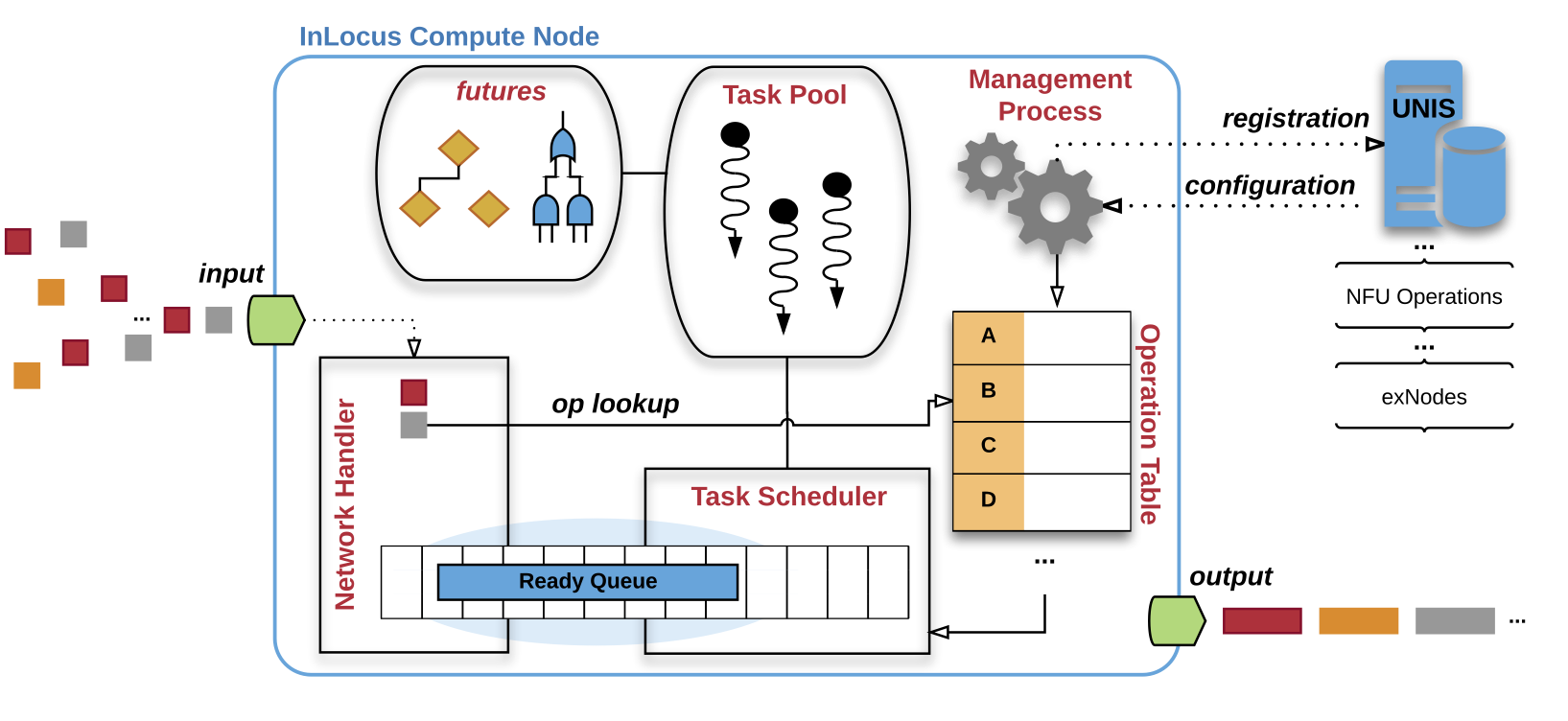
With proliferating sensor networks and Internet of Things-scale devices, networks are increasingly diverse and heterogeneous. To enable the most efficient use of network bandwidth with the lowest possible latency, we are developing InLocus, a stream-oriented architecture situated at (or near) the network's edge which balances hardware-accelerated performance with the flexibility of asynchronous software-based control. Although InLocus is a general, platform-agnostic framework, we focus our research on Field-Programmable Gate Arrays (FPGAs) implementation, thus leveraging the performance and flexibility of custom hardware in a Programmable Logic device.
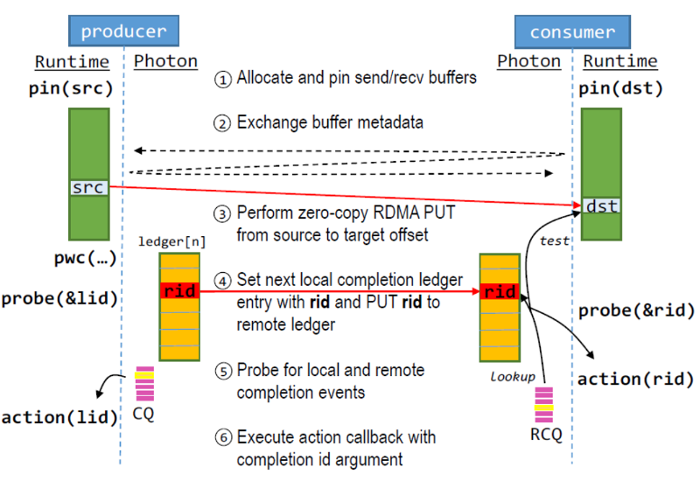
RDMA Networking
Hardware Acceleration of PyTorch Distributed Collective Communication Operations
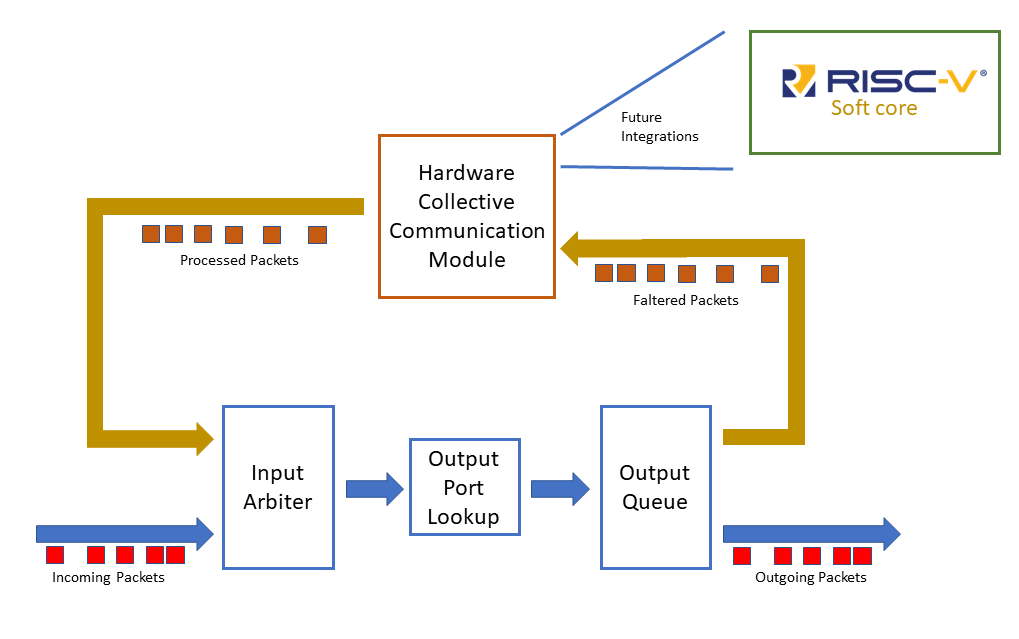
Over 20% of the core hours in super computing resources in Science and Technology domain is utilized for collective communication operations. Hence, optimizing these operations would entail significant boost in computation performance for majority of scientific domains. This project focuses on offloaded collective operations to hardware through Field Programmable Gate Arrays (FPGAs) to improve their performance in-terms of computations such that the associated delays are dependent on the network status. Current direction of the project focuses on static implementation of collective operations on hardware with software level association to PyTorch Distributed Communication operations. In the long run, RISC-V soft-cores would be utilized to introduce flexibility of operations while thriving to maintaining the accelerations achieved through the static hardware-based implementations.
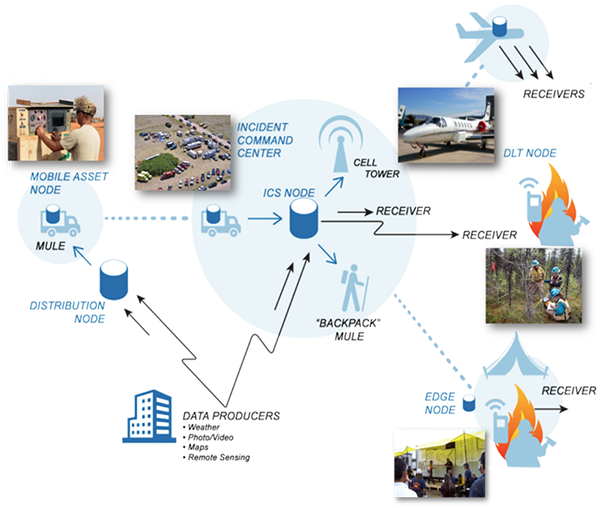
Data Logistics
Declarative Network Programming
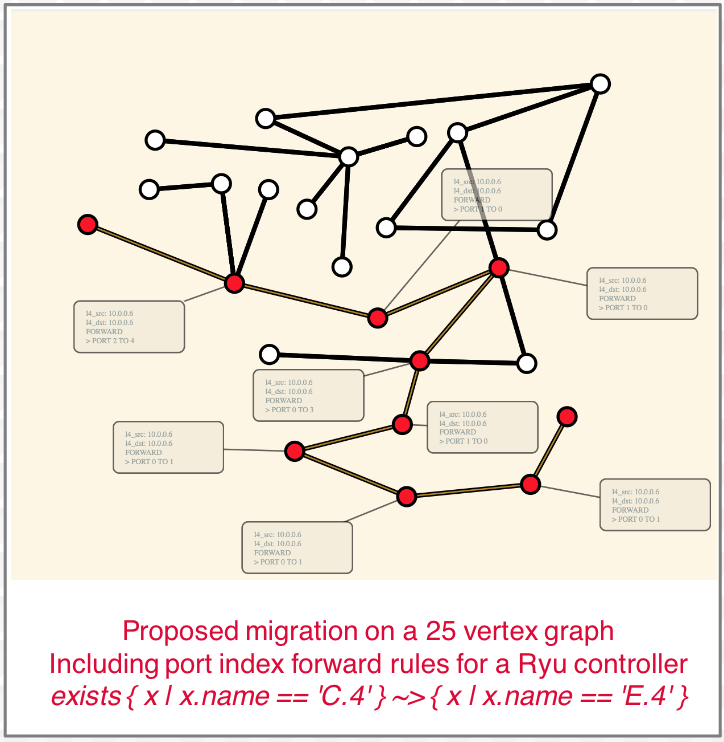
Network Monitoring and Analysis
